maptalks 1.0.0-rc.29版本发布

前言
有的同学可能会问:只是发个版本而已,需要特地的写篇文章来介绍吗? 为什么要写这篇文章呢?我认为这个版本是核心库最近两年最重要的版本,因为这个版本里引入一些新的思想和方法,为后续的版本迭代和优化打开了新的大门,可以说是一个里程碑版本 且这个版本里涉及一些纯干货的技术,故在这里特地介绍下
主要更新内容
- 优化mousemove事件
- 优化worker通信的时机和频率
- 引入渐进渲染
- 引入时间切片
- 一些bug修复
GIS中性能的重要性
从上面的更新内容可以看出,本次主要的更新内容都和性能有关,这个不是偶然,而是有GIS的特殊性决定。 GIS引擎承载的数据量不像我们平时的MIS业务,其数据量实在是庞大, 少则几十条,多则过百万条(比如城市级别的建筑物数据), 即使你的GIS引擎功能做的再优秀,如果性能和体验不行的话,也不能称之为出色的引擎, 所以性能是GIS引擎一个重要的指标。
GIS中性能一直是个令人非常头疼的难题,主要体现在:
- 数据量大,数据量都是以万为单位进行计数
- 网络请求量大且重,比如3dtile数据,矢量切片的数据
- 很多优化手段都用不上,例如离屏canvas的缓存,脏矩形的渲染等,因为地图支持缩放,旋转,倾斜, 改变中心点等,当地图的视角改变时导致渲染的结果缓存全部失效, 必须得全部数据进行重绘,从而使这些常规的优化手段用不上, 这些优化手段在普通的canvas应用上是非常有效的, 但是在GIS不行,好在经过这两个月的学习和探索终于让我们找到了新的或者说是非常规的优化手段
- 实时渲染,类游戏引擎,即使地图处于静止状态,但是地图上的数据可能处于动画状态,因为每帧只有16ms,必须要要求所有数据在一帧内渲染完整,否则就要卡了
优化mousemove事件
mousemove事件是整个引擎里最吃性能的事件了,因为其触发的频率比较高,所以这个版本里我们做了节流(throttle)控制,默认是48ms, 你可以根据自己的业务需要调整这个参数mousemoveThrottleTime
var map = new maptalks.Map("map", {
center: [108.37895325, 31.3523049],
zoom: 4,
pitch: 45,
centerCross: true,
doubleClickZoom: false,
cameraInfiniteFar: true,
mousemoveThrottleTime: 48,
baseLayer: new maptalks.TileLayer("base", {
urlTemplate:
"https://{s}.basemaps.cartocdn.com/light_all/{z}/{x}/{y}.png",
subdomains: ["a", "b", "c", "d"],
attribution:
'© <a href="http://osm.org">OpenStreetMap</a> contributors, © <a href="https://carto.com/">CARTO</a>',
}),
});意这个值越大性能越好,但是灵敏度会下降,所以要设置合适的值,不可太大, 如果需要关闭这个功能,可以把mousemoveThrottleTime设置为负值即可,比如-1
var map = new maptalks.Map("map", {
center: [108.37895325, 31.3523049],
zoom: 4,
pitch: 45,
centerCross: true,
doubleClickZoom: false,
cameraInfiniteFar: true,
mousemoveThrottleTime: -1,
baseLayer: new maptalks.TileLayer("base", {
urlTemplate:
"https://{s}.basemaps.cartocdn.com/light_all/{z}/{x}/{y}.png",
subdomains: ["a", "b", "c", "d"],
attribution:
'© <a href="http://osm.org">OpenStreetMap</a> contributors, © <a href="https://carto.com/">CARTO</a>',
}),
});视屏里演示了3dtile图层单位时间内连续identify 8次优化前后的性能对比
- 左边为优化前
- 右边为优化后
map.on("mousemove", (e) => {
const time = "identify";
console.time(time);
for (let i = 0, len = 8; i < len; i++) {
const result = layer.identify(e.coordinate);
}
console.timeEnd(time);
});优化worker通信的时机和频率
maptalks里引擎支持的部分图层有:
- 3dtile图层(Geo3DTilesLayer)
- 矢量切片图层(VectorTileLayer/GeoJSONVectorTileLayer)
- 常规的点线面图层(PointLayer/LineStringLayer/PolygonLayer)
- three图层(ThreeLayer)
这些图层因为涉及到大量的数据请求,数据解析,图形几何体(Geometry)的构造, 放到主线程里做这些事情显然是不可能的了,能把主线程卡成翔,所以maptalks里引入worker功能, 把这些功能放到worker里来做来解决主线程卡的问题。
worker使用时可以在worker里返回arraybuffer,利用Transferable object来解决数据克隆的性能问题,主要有:
- webgl的属性数据(position,normal,uv等),TypeArray.buffer的值
- 纹理数据(imagebitmap),比如3dtile的纹理数据
是有些数据是无法利用worker Transferable object的,比如矢量切片里的要素数据,因为pbf解码出来是个json object,且主线程里又必须要用到这个json object 根据我们的测试发现worker通信(postMessage)也成为了瓶颈,体现在:
- 矢量切片和3dtile图层里会产生大量的网络请求,worker通信太频繁了
- 矢量切片pbf数据解码出来是json,当pbf数据体积大了后(有的pbf解码出来的json得有几M), 消息通信时clone这些数据会导致worker通信非常耗时
有的同学可能会问:
- 不可以在worker里也可以返回arraybuffer来解决通信的耗时的问题吗?这个是可以的, 但是在主线程里还是需要将这个arrraybuffer解码成json object,所以并不能解决主线程卡的问题
- worker里不能直接返回pbf文件的arraybuffer吗?这个也是可以的, 但是还是需要再主线程里还是需要将pbf arraybuffer解码成json object
经过我的测试浏览器里如何将pbf的数据以json对象的方式返回给主线程的几种方式,他们的性能对比如下
| 方法 | 性能表现 | 操作方法 | 备注 |
|---|---|---|---|
| structuredClone | 最优 | worker里进行pbf parse,然后把json对象利用postMessage发送给主线程 | worker 底层的数据克隆用的就是 structuredClone |
| PBF parse | 其次 | worker里直接返回pbf arraybuffer,主线程里进行pbf parse | 主线程里进行arraybuffer=>json object |
| JSON.parse | 最差 | worrker里返回json string,主线程里进行JSON.parse | postMessag(data:jsonstring)要一次耗时,主线程里JSON.parse还得来一次 |
这个表格结果是我测试得出的,如果大家有不同的意见或者有更好的方法,欢迎在评论区留言
通过上面的表格我们可以得出: 直接在worker里向主线程里发送json object是性能最优的方式,瓶颈在worker通信太频繁和数据体积比较大, 致使worker里向主线程进行postMessage时成为瓶颈
引入requestIdleCallback
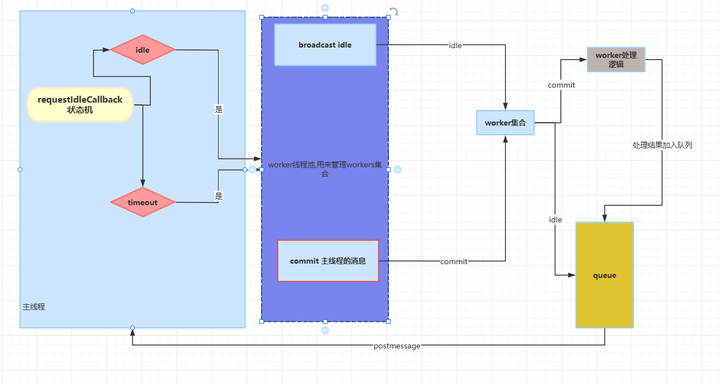
关于requestIdleCallback的使用这里我就不多介绍了,请参阅MDN requestIdleCallback可以检测到当前页面是否空闲(idle),那么灵感就来了,我们可以从这里入手,主要思路为:
- 当主线程繁忙时不要往worker里发送任务,发了也是白发,一直卡在那里
- worker里处理完任务时,不要直接将结果postMessage到主线程, 因为主线程可能很忙,而是在worker里维护一个队列,当主线程处于idle时, 让主线程主动告诉worker,worker收到idle消息后把处理的结果这时再发送给主线程
let broadcastIdleMessage = true;
function loop() {
if (broadcastIdleMessage) {
getGlobalWorkerPool().broadcastIdleMessage();
} else {
getGlobalWorkerPool().commit();
}
executeMicroTasks();
broadcastIdleMessage = !broadcastIdleMessage;
}总之就是当且仅当主线程idle时,再进行worker通信,以此来控制worker通信的时机和频率, 从而来减少主线程繁忙程度
支持自定义worker通信参数的配置
const GlobalConfig = {
//dev env
dev: false,
//test env
test: false,
//idle logging
idleLog: false,
//idle 时间阈值
idleTimeRemaining: 8,
//idle 超时阈值
idleTimeout: 1000,
//worker 数量
workerCount: 0,
//worker 通信并发数量
taskCountPerWorkerMessage: 5,
};这个是引擎的全局配置对象,可以在maptalks.GlobalConfig上进行修改,配置合适的值
- idleLog 日志
- idleTimeRemaining 判断主线程idle的阈值
- idleTimeout 超时阈值
- taskCountPerWorkerMessage worker通信并发的数量,即每个worker里一次能向主线程发送的消息的数量
maptalks.GlobalConfig.idleLog = true;
//or
import { GlobalConfig } from "maptalks";
GlobalConfig.idleLog = true;相关问题
- 如果主线程一直不idle怎么办?requestIdleCallback里我们设置了timeout了, 且这个参数你是可以配置的
- 这样就可以解决主线程卡的问题了吗?不一定,这个只是用来解决worker通信的问题的, 主线成是否卡还得有主线程的逻辑来决定的,worker返回的数据,如果主线程里处理的逻辑差的话照样卡
- worker里的队列会导致消息积压吗?不会的,因为主线程里我们已经控制了向worker提交的时机了, 只有空闲时才会提交信息,不是野蛮的往worker里提交信息的, 所以worker里不会接收到大量的信息的,且worker是个线程池, 分摊到每个worker其实没有几条消息,假设主线程忙,主线程是不会像worker里提交信息的
引入渐进渲染(Progressive Render)
maptalks里有个矢量图层叫VectorLayer,关于VectorLayer:
- 底层是用canvas渲染的
- 是maptalks核心库的唯一的矢量图层,诞生的比较早
- 当然现在maptalks也支持了webgl渲染,具体参考 maptalks/maptalks-gl-layers
canvas相对于webgl渲染的数据量不大,但是其也有其自己的优点:
- 兼容好
- 渲染效果好,阴影,渐变,文字,锯齿等
- 数据更新速度快
maptalks内部渲染采用 requestAnimFrame控制整个地图的渲染的
但是由于canvas的渲染瓶颈的存在,导致一帧内canvas能渲染的数据量是有限的,一般在1-2千个,当数据达到多少w时,就开始卡了,为了解决这个问题,这个版本里对VectorLayer加了渐进渲染的支持
渐进渲染(Progressive Render)的本质:
- 对数据进行分页:比如一万条数据每页1000条,那就有10页,这个很好理解
- 对每次渲染的结果进行快照(snapshot),下一帧渲染时,先绘制快照,然后再绘制当前页的数据
相关问题
- 是么是快照?即每次图层渲染完了图层渲染的渲染结果绘制到另一个缓存的canvas
_snapshot() {
const progressiveRender = this.isProgressiveRender();
const geosToDraw = this._geosToDraw || [];
for (let i = 0, len = geosToDraw.length; i < len; i++) {
const geo = geosToDraw[i];
const t = geo._hitTestTolerance() || 0;
this.maxTolerance = Math.max(this.maxTolerance, t);
if (progressiveRender) {
this.pageGeos.push(geo);
const painter = geo._painter;
this.geoPainterList.push(painter);
}
}
if (!progressiveRender) {
return this;
}
const time = now();
const snapshotCanvas = this._checkSnapshotCanvas();
if (snapshotCanvas && this.canvas) {
const ctx = clearCanvas(snapshotCanvas);
ctx.drawImage(this.canvas, 0, 0);
}
const layer = this.layer;
const { progressiveRenderCount } = layer.options;
const geos = layer._geoList || [];
const pages = Math.ceil(geos.length / progressiveRenderCount);
this.renderEnd = this.page >= pages;
if (this.renderEnd) {
this._setDrawGeosDrawTime();
}
if (isDebug(this.layer)) {
console.log('snapshot time:', (now() - time) + 'ms');
}
this.page++;
return this;
}- 是么叫先绘制快照?即每次图层绘制时先把快照缓存的结果绘制到图层上,然后在绘制当前这个帧内的数据,即当前页的数据
_drawSnapshot() {
if (!this.isProgressiveRender()) {
return this;
}
const { snapshotCanvas, context } = this;
if (!snapshotCanvas || !context) {
return this;
}
const map = this.getMap();
if (!map) {
return this;
}
const dpr = map.getDevicePixelRatio() || 1;
const rScale = 1 / dpr;
context.scale(rScale, rScale);
context.drawImage(snapshotCanvas, 0, 0);
context.scale(dpr, dpr);
return this;
}使用方式
使用起来很简单,在初始化VectorLayer时配置下开启即可(progressiveRender),业务里根据自己的业务数据的复杂度配置合适的每页数据量
- 点的数据一般在1000个左右
- 复杂的面在500个左右
- 线在1000个左右
layer = new maptalks.VectorLayer("layer", {
forceRenderOnMoving: true,
forceRenderOnZooming: true,
forceRenderOnRotating: true,
progressiveRender: true,
progressiveRenderCount: 1000,
progressiveRenderDebug: false,
}).addTo(map);视频里演示9.5w条水系数据渲染效果
注意
因为canvas每帧渲染数据量的限制,所有当地图处于快速交互时(动画,pitching,rotating时)会只拿当前渲染帧对应的数据来渲染,是无法渲染全量的数据的,否则又卡了。 在下面情况下,图层将重头渲染的:
- 图层上图形进行动态添加和移除时
- 图形的样式进行更新
- 图形的形状改变时
- 图形zindex改变
- 图层状态改变
相对于webgl渲染器体验要差点,但是可以做到大数据量数据不卡了, 而且测试下来20w的点数据,10w的polygon数据可以做到事件流畅交互,很适合静态数据的渲染展示和可视化
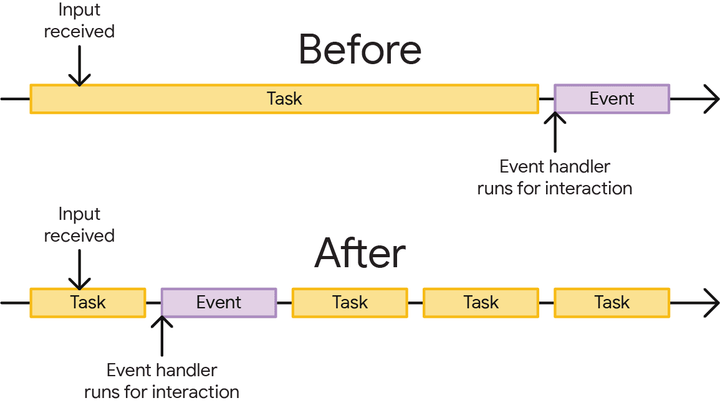
引入时间切片
maptalks里除了渲染方面,也有其他的功能是long task,比如:
- Geometry的创建
- GeoJSON数据parse
- layer.identify操作
- 其他等
为了解决long task卡页面的问题,我们引入了时间切片来解决这些问题,利用promise是micro task的特性,本质就是将一个大任务切割成多个小任务,然后调度这些任务集合直至所有任务完成,最后进行promise.resolve
在maptalks里我们提供了MicroTask模块来干这件事情,runTaskAsync方法就是用来运行一个时间切片任务的函数
maptalks.MicroTask.runTaskAsync({ count, run }).then((results) => {});
maptalks.MicroTask.runTaskAsync({ run }).then((results) => {});
//or
import { MicroTask } from "maptalks";runTaskAsync适用以下场景:
- 大任务,比较耗时的,会卡主线程的
- 大任务且这个任务可以别分解
toGeometryAsync(geojson)
geojson反序列化我们提供了异步版本,可以做到大规模的数据反序列化不卡主线程,其内部实现也是基于MicroTask模块的
const time = "异步方法parse geojson";
console.time(time);
maptalks.GeoJSON.toGeometryAsync(globalGeoJSON, null, 3000).then((geos) => {
console.timeEnd(time);
console.log(geos);
});视频里演示了9.5w水系数据geosjon反序列化的性能表现
自定义micro task
时间切片功能我在引擎做了个独立的模块(MicroTask),并开放出来了 runTaskAsync方法
- 后续maptalks内部的功能也会基于这个模块来进行优化
- 开放出来方面用户来自定义自己的micro task
- toGeometryAsync(geojson) 也是基于 runTaskAsync方法
使用方式:
maptalks.MicroTask.runTaskAsync({ count, run }).then((results) => {});
maptalks.MicroTask.runTaskAsync({ run }).then((results) => {});- count 函数运行次数
- run 任务函数,可以在函数里定义你的任务逻辑
- 当只传入函数时,表示这个函数被运行一次
举例
下面我们来演示个clone 100w对象的例子,来看看具体怎么使用
function createObject() {
return {
type: "Feature",
geometry: {
type: "Point",
coordinates: [120.61868009903321, 31.16788501911506],
},
properties: {
name: "2-8b54a3",
_color: "",
center: [120.61868009903321, 31.16788501911506, 0],
},
};
}
function cloneDataSync(data) {
if (structuredClone) {
return structuredClone(data);
}
return JSON.parse(JSON.stringify(data));
}
function generateData() {
const data = [];
while (data.length < 100 * 10000) {
data.push(createObject());
}
return data;
}
const data = generateData();
function testSync() {
const time = "testSync";
console.time(time);
const t = maptalks.Util.now();
const cloneData = cloneDataSync(data);
const message = `testSync time:${maptalks.Util.now() - t}ms`;
showMessage(message);
console.timeEnd(time);
console.log(cloneData);
}
function testAsync() {
const time = "testAsync";
console.time(time);
const t = maptalks.Util.now();
const pageSize = 10000;
const count = Math.ceil(data.length / pageSize);
let page = 1;
const run = () => {
const startIndex = (page - 1) * pageSize,
endIndex = page * pageSize;
const list = data.slice(startIndex, endIndex);
page++;
return cloneDataSync(list);
};
maptalks.MicroTask.runTaskAsync({ count, run }).then((results) => {
const list = [];
results.forEach((result) => {
for (let i = 0, len = result.length; i < len; i++) {
list.push(result[i]);
}
});
const message = `testAsync time:${maptalks.Util.now() - t}ms`;
showMessage(message);
console.timeEnd(time);
console.log(list);
});
}测试代码里有两个函数:
- testSync 主线程里直接执行
- testAsync 利用microtask异步执行
- 这个是在我的电脑上测试,异步方法比同步的方法还要快点,注意不同的浏览器和硬件环境下结果可能不同
视屏里演示两者的差异,明显看到testAsync方法是不卡主线程的
相关问题
- 时间切片的方法一定比同步方法慢吗?不一定,举个例子:我要搬砖,一共10块转,方式1: 一次搬搬10块,只需要一次,但是搬的过程中,极度不稳定,摇摇欲坠,脚下的步伐怎么也快不起来 。 方式2:一次搬2块,5次,虽然需要5次,但是每次搬的过程中都是轻松加愉快,步伐快的飞起,那么问题来了,两次那个时间更短呢?这个就不好说了,因为量变会质变
- runTaskAsync 里的任务是怎么调度?利用的是requestIdleCallback或者requestAnimationFrame, 优先requestIdleCallback,浏览器不支持requestIdleCallback时会自动回退到requestAnimationFrame
- runTaskAsync 的运行时间可以估算吗?不可以,因为整个任务集合是有requestIdleCallback调度的, 如果当前页面里有其他的任务导致主线程繁忙这时microtask将处于等待状态,所以他的执行时间和页面是否繁忙程度有关
- runTaskAsync 适用任何场景吗?不是的,如果一个大任务不能被切割就不要使用它了, 其价值就是切割大任务,但是我们平时代码里的任务基本都是可以被切割和分解的
适用场景
- 大文件切割和上传
- 大规模的数据的克隆
- 大图片的处理
- 大规模的数据反序列化
- 大规模的地理数据进行空间计算,比如有10w个点,查询这些点哪些落在上海市
- 其他等
最后
这个版本只是一个开始,后续maptalks内部一些功能也会采用这里的介绍的方法和思想来进行优化